Anime Illustration Colorization Part 2

Originally posted on My Medium.
Introduction
This is an update on my previous article Anime Illustration Colorization Part 1. If you have not read that, I recommend you to read it first and then come back.
After posting the previous article, I have done a few things to try to improve the performance of the model.
1. Cleaning The Dataset
Since I scraped the dataset automatically from the internet, there are some useless images in the dataset.
Although I have filtered out some unwanted images by keywords and tags when scraping, there are still some outliers (gray images, sketches, product catalogs, tutorial or announcement images…).
For gray images, I simply wrote a script to automatically remove them from the dataset.
But for the others, the only way I could think of was to skim through all the images and remove them manually.
2. Updating Color Hints Input
Instead of color dots only, I updated the color hints images to contain both dots and lines in random positions with the corresponding colors.
I also changed the background from white to black such that it is able to draw white hints on it. Although it turns out we cannot draw black hints anymore, this is fine since I realized a black color #000000 is rarely used in paintings except for lines and borders.
The better solution to this issue would be using a transparent background (RGB → RGBA). However, this will increase the dataset size and the training time unnecessarily for this project. So, for simplicity, I decided to use black background here instead.
3. Increasing Image Size in Training
Originally, I trained the Pix2Pix model with an input size of 256×256. Now I simply increased it to 512×512 and here are some results after training for 100 epochs:
(From left to right: Input image, Input hints, Ground truth, Predicted result)





4. Testing with Arbitrary Size Images
Since both the U-Net and the PatchGAN in our Pix2Pix model are fully convolutional, there should be no limitations on the input size. But remember that our U-Net contains concatenation layers. We have to make sure that the inputs of every concatenation layer are in the same shape. Otherwise, we may run into ConcatOp: Dimensions of inputs should match error.
We are using padding="same" in every convolutional and transposed convolutional layer. The output sizes of each of them are calculated as follows:
- Convolution layer with
padding="same":
size_out = ceil(size_in / stride)- Transposed convolution layer with
padding="same":
size_out = size_in * strideThe tricky part here is the ceil(size_in / stride) . If the input size of that layer is not divisible by the stride length, the ceiling operator will round the number up. This often results in having a different size from its concatenation partner on the up-sampling side.
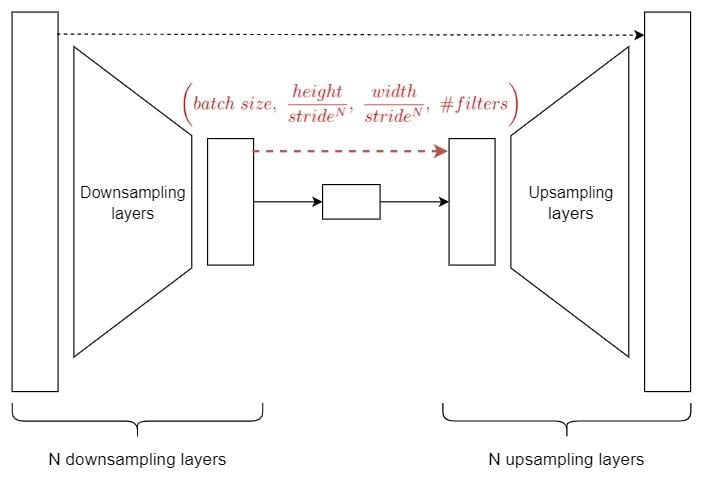
To cope with this issue, we need to pad/crop the input image to make sure its convoluted size is divisible by the stride length in every down-sampling layer. Assuming that the stride lengths of all the down-sampling Conv layers are the same, the input height and width should match the following conditions:
height % (stride ^ N) = 0width % (stride ^ N) = 0
Where N is the number of down-sampling layers.
As you can notice, the deeper the U-Net, the more chances that we have to pad the image, and the more chances of having a much larger input. With very limited hardware resources, it is easy to get a Resource exhausted: OOM when allocating tensor with shape [...] error when inputting a very large image. So I limited the number of down-sampling layers to 7, such that with strides=2 , we only have to pad the image so that its height & width are divisible by 2^7 = 128 .
The following are some results after training for 120 epochs:

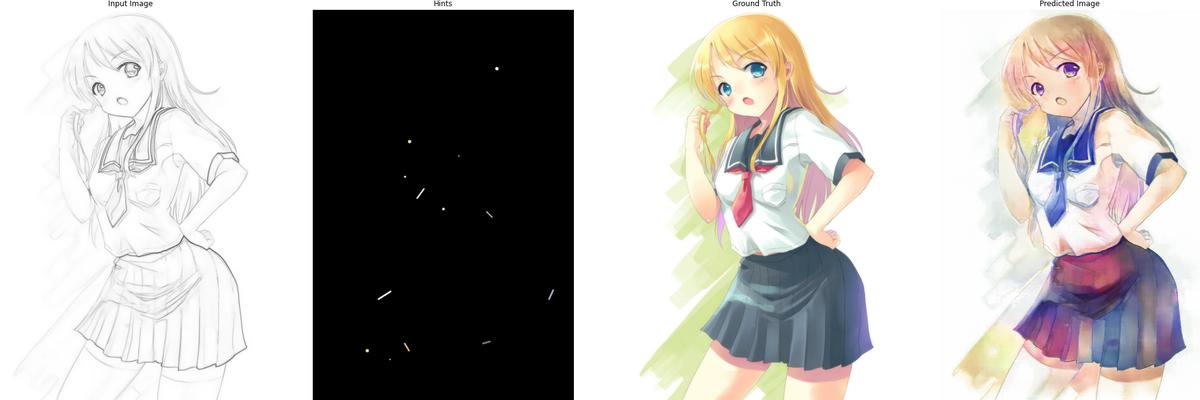


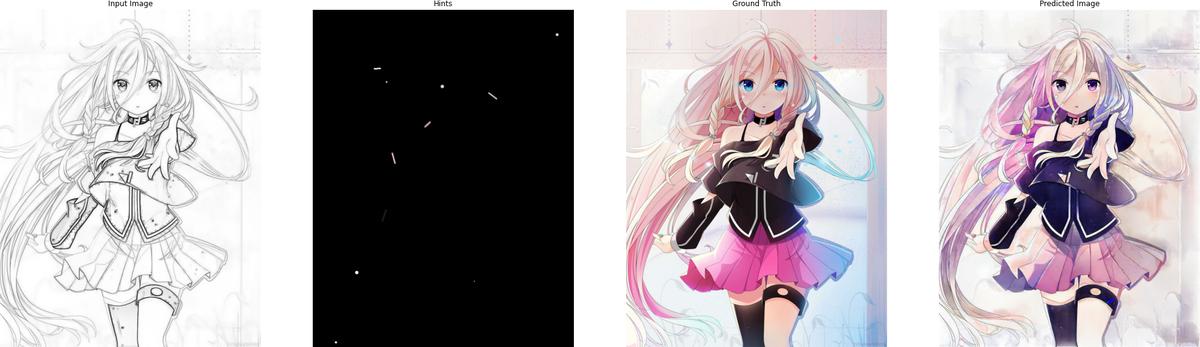

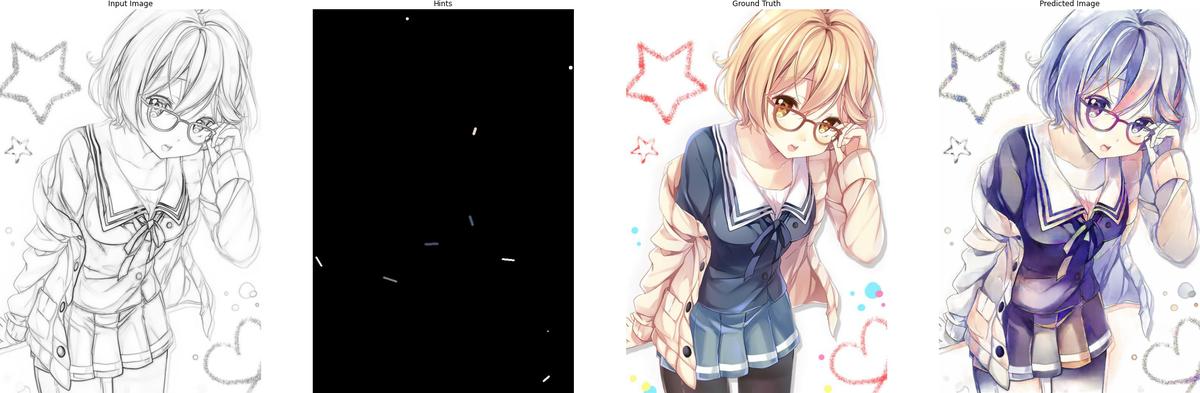


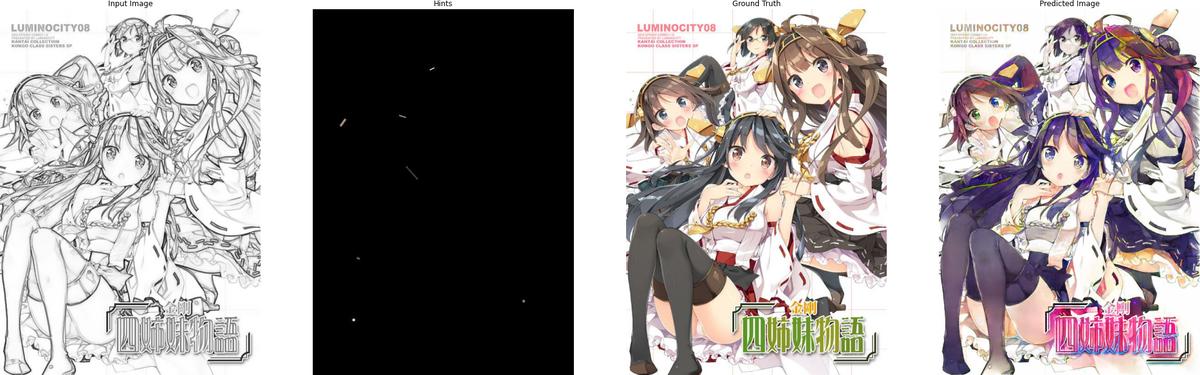
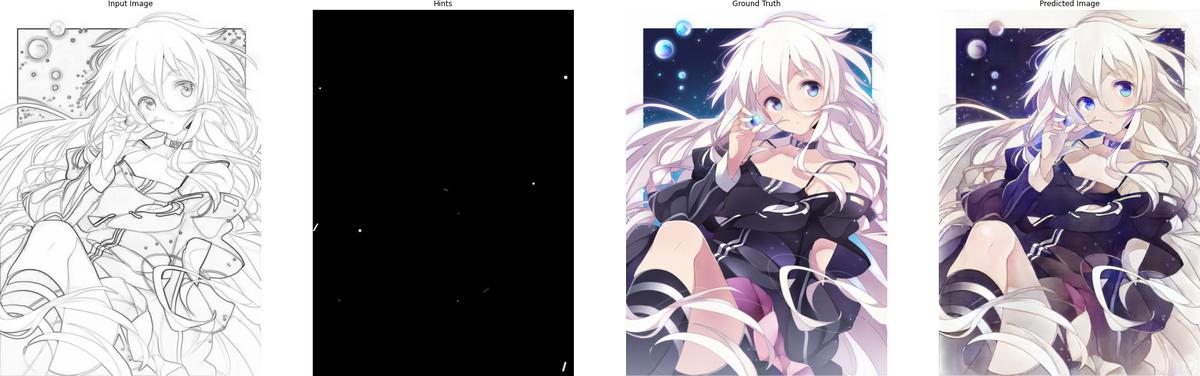
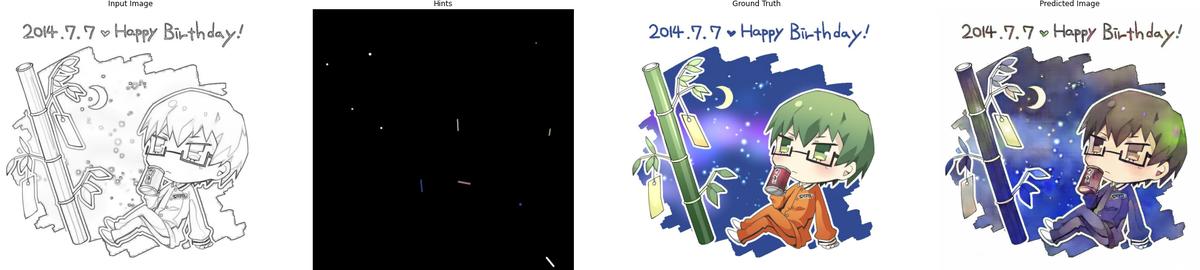


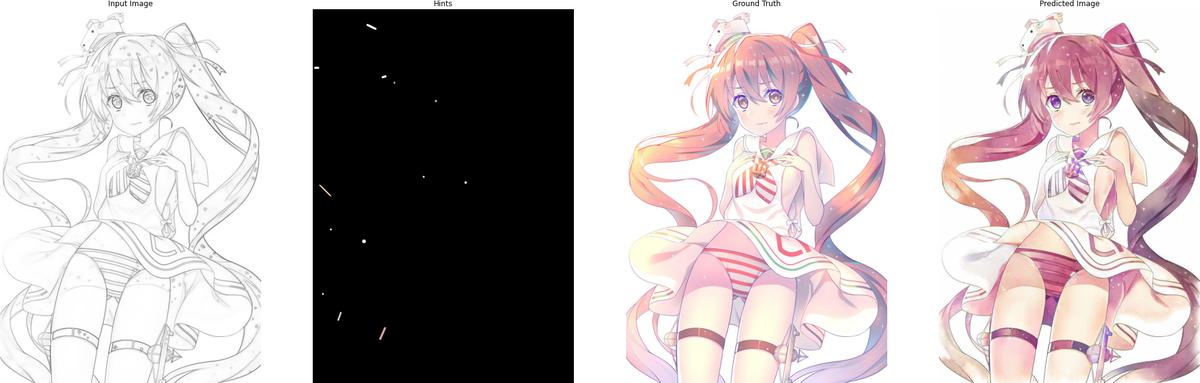
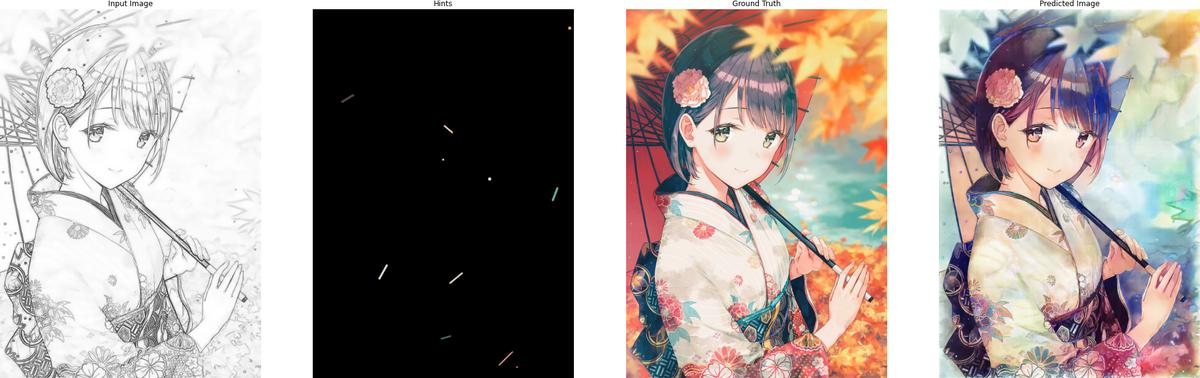

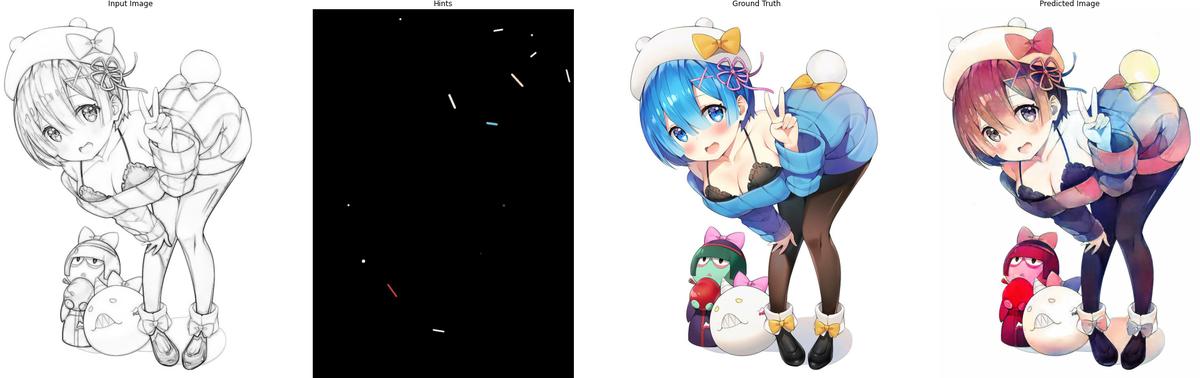
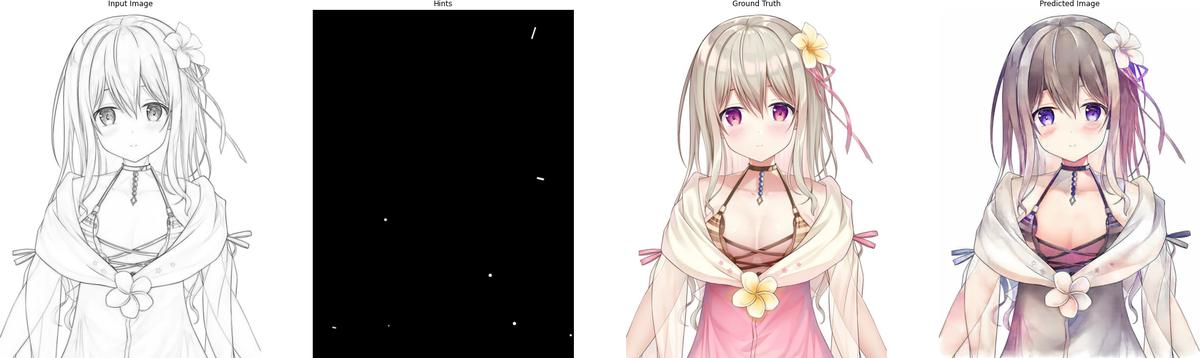
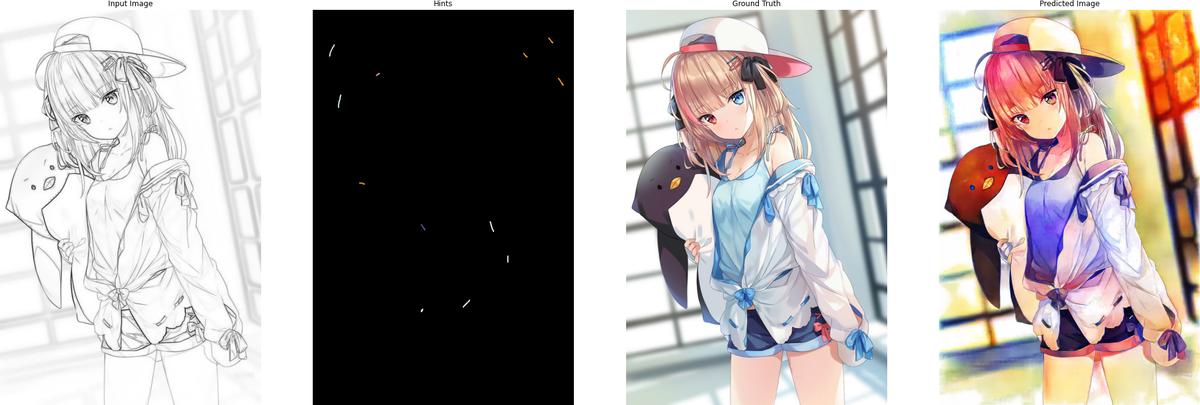

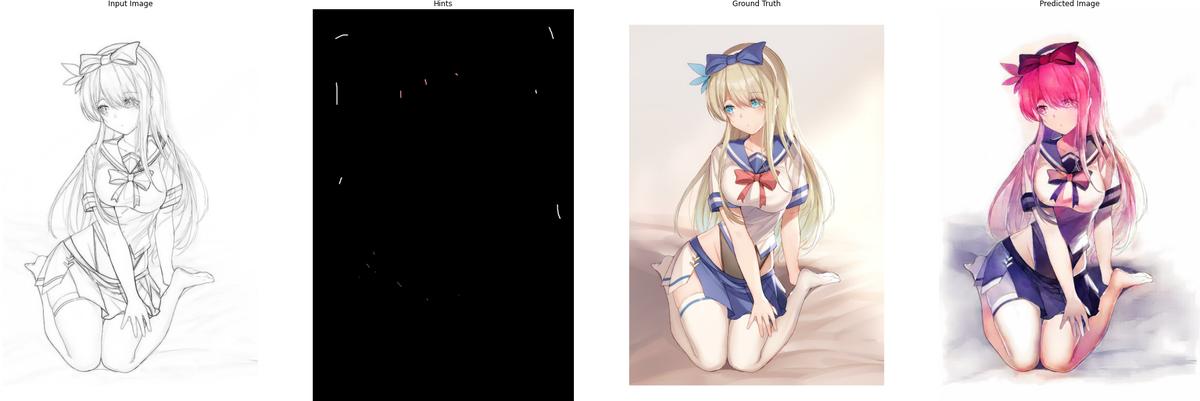

5. Conclusion
The results are quite impressive to me. But obviously, there is still a lot of room for improvement. The following is the checklist for future work on this project:
- Colors sometimes leak into surrounding areas
- Try other model architectures
Once I have time and ideas, I will come back to this project. Thank you for reading.





