DiagonalGAN — Content-Style Disentanglement in StyleGAN Explained!
Paper Explained: Diagonal Attention and Style-based GAN for Content-Style Disentanglement in Image Generation and Translation

Originally posted on My Medium.
Introduction
In image generation, Content-Style Disentanglement has been an important task.
It aims to separate the content and style of the generated image from the latent space that is learned by a GAN.
- Content: spatial information (e.g. face direction, expression)
- Style: other features (e.g. color, strokes, makeup, gender)
This DiagonalGAN paper proposes a method to disentangle the content and style in StyleGAN.
StyleGAN Problem
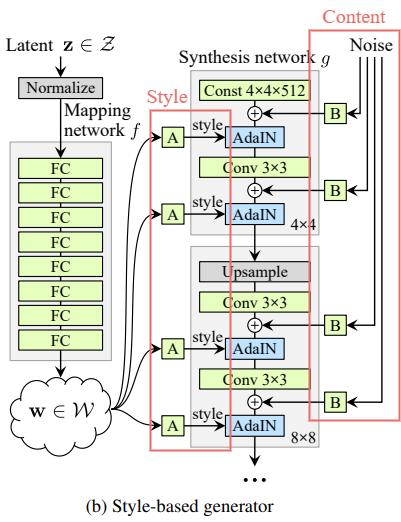
StyleGAN tries to disentangle the style and content using the AdaIN operation.
However, the content controlled by per-pixel noises is mostly for minor spatial variations. Therefore, the disentanglement of global content and style is by no means complete.
DiagonalGAN
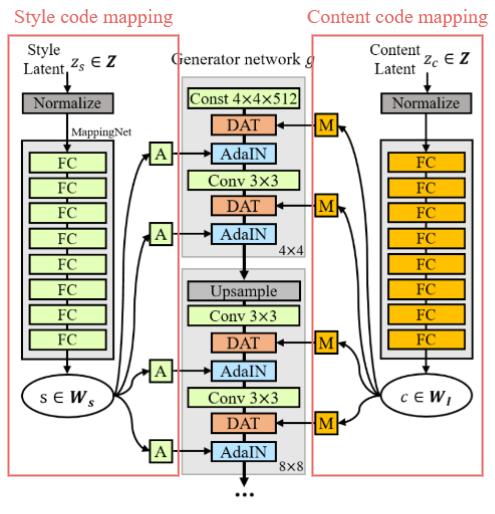
This paper proposes to:
- replace the per-pixel noises with a content code mapping module similar to the style code mapping module.
- use the DAT (Diagonal Attention) layer to control the content.
Theory
It is found that the normalization and spatial attention modules have similar structures that can be exploited for style and content disentanglement.
Specifically, the AdaIN and attention formulas can be written in matrix forms.

AdaIN
The AdaIN can be represented as Y=XT+R:

Here, I use C=3 (RGB) for a clearer illustration of the idea. In intermediate activations, C usually equals the number of filters used in the convolution layer.
Attention
The spatial attention (e.g. self-attention) can be represented as Y=AX, where A is a fully populated matrix of size HW×HW.
Since the transformation matrix A is applied to a pixel-wise direction to manipulate the feature values of a specific location, it can control the spatial information such as shape and location.
Diagonal Attention
We can mix the attention and the AdaIN by writing Y=AXT+R, where A controls the content and T controls the style of the image.

Compare to StyleGAN
In StyleGAN, the content code C generated from the per-pixel noises via the scaling network \text{B} is added to feature X before entering the AdaIN layer (i.e. Y=(X+C)T+R).
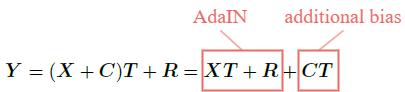
By expanding it, we get the original AdaIN formula plus an additional bias CT, which is different from spatial attention because that is multiplicative to feature X.
Although one could potentially generate C so that the net effect is similar
to AX, this would require a complicated content code generation network. This explains the fundamental limitation of the content control in the original StyleGAN.
DAT Layer

A=(I+\beta\ \text{diag}(d))- d: d \in W_c is a differential attention map of dimension H×W.
- \beta: used to calibrate whether the layer is responsible for minor or major changes, so as to prevent overemphasizing minor changes.
- \text{diag}(d): denotes the diagonal matrix whose diagonal elements are d.
The diagonal spatial attention is multiplicative (i.e. A multiplies X) so that we can control global spatial variations.
Loss Function
L_{total} = L_{adv} + L_{ds}- L_{adv}: non-saturating adversarial loss with R_1 regularization.
- L_{ds}: Diversity-Sensitive loss which encourages the attention network to yield diverse maps.
L_{ds} = \max (\lambda - \| G(z_s, z_c^1) - G(z_s, z_c^2) \|_1, 0)The objective of L_{ds} is to maximize the L_1 distance between the generated images from different content codes z_c^1, z_c^2 with the same style code z_s (i.e. make them as diverse as possible).
The threshold \lambda is used to avoid the explosion of the loss value.
Results

The images on the second row are generated with changing content codes at entire layers under the fixed style code.
The images in the following rows are sampled with changing the content codes at specific layers while fixing those of other layers.
You can see that the overall attributes of the face (style) do not change while the face direction, smiling, etc. (content) change when we adjust the content codes in a hierarchical manner.


- (a): source image generated from arbitrary content and style codes.
- (b): varying style codes with fixed content codes.
- (c): varying content codes with fixed style codes.
- (d): varying both codes.
Direct Attention Map Manipulation

By controlling the specific areas of attention, we can selectively change the facial attributes.
- (a): 1st 4×4 attention map: control face direction by changing the activated regions.
- (b): 2nd 8×8 attention map: control mouth expression with high values on larger mouth areas.
- (c): 2nd 16×16 attention map: control the size of eyes by changing activated pixel areas of the eyes.
Code
References
[1] G. Kwon and J. Ye, “Diagonal Attention and Style-based GAN for Content-Style Disentanglement in Image Generation and Translation”, arXiv.org, 2022. https://arxiv.org/abs/2103.16146
[2] G. Kwon and J. Ye, “DiagonalGAN”, Github, 2022. https://github.com/cyclomon/DiagonalGAN


")
")

