Anime Illustration Colorization Part 1

Originally posted on My Medium.
Introduction
This project aims to create a deep learning model to learn a mapping from a non-colored anime illustration (sketch) to a colored version. We will use the Pix2Pix GAN to achieve this.
1. Dataset
First of all, we need a dataset, a dataset that contains a set of non-colored images and a set of colored images. Since we will use Pix2Pix to learn the mapping, we need a dataset with paired images (non-colored images and colored images should be in pairs). The following is an example of a pair.

However, it is hard to find a dataset that contains such an amount of paired images on the internet. So, I created a new dataset by scraping anime artwork from the internet and then wrote a python script to extract lines from these images using the OpenCV library.

The constructed dataset contains 18000+ paired images. 70% will be used for training and 30% will be used for testing.
For those who are interested in how I extract lines from an image, I simply do a dilate and then a divide:
se = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (6, 6))
bg = cv2.morphologyEx(img, cv2.MORPH_DILATE, se)
result = cv2.divide(img, bg, scale=255)This method is not perfect for all images. For some dark and complicatedly colored illustrations, the extraction results are not pretty desired.

If you have better methods to extract lines from these artworks, please leave a comment and let me know.
2. Model
There are a lot of different deep-learning models out there that can be used for learning colorization mapping. In this project, I am going to use Pix2Pix to solve the problem.
Architecture
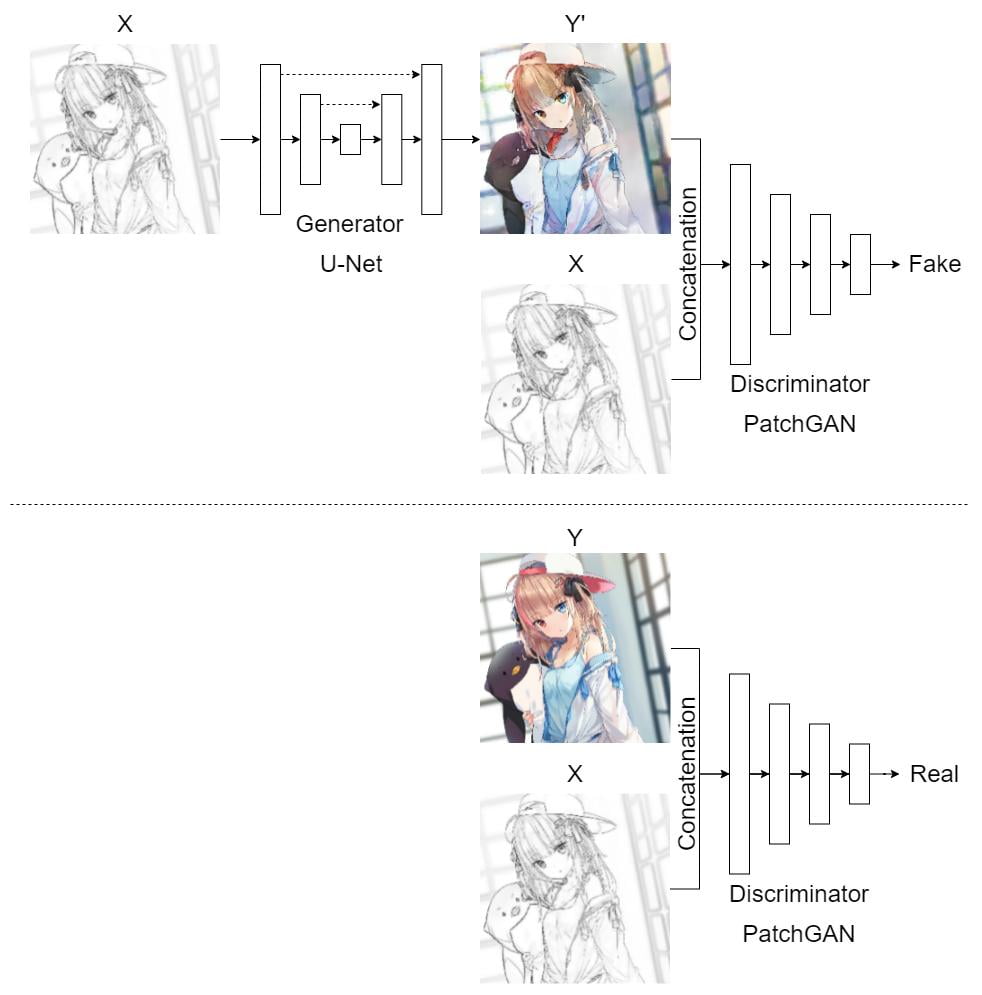
We will use a U-Net and a PatchGAN as the generator and the discriminator respectively as proposed in the Pix2Pix paper.
How it works (roughly)
The Pix2Pix model is a GAN, or specifically, it is a type of conditional GAN (cGAN). Just like a GAN, Pix2Pix trains the generator and the discriminator simultaneously. But instead of taking samples from a latent space, the Pix2Pix generator takes images as inputs.
In this model, the generator will learn a function to map non-colored images X to colored images Y. It tries to fool the discriminator that the generated images are real and are from the target domain. Meanwhile, the discriminator will try to learn a function to correctly classify fake and real images.
For detailed codes of the Pix2Pix model, you can check out this Tensorflow tutorial.
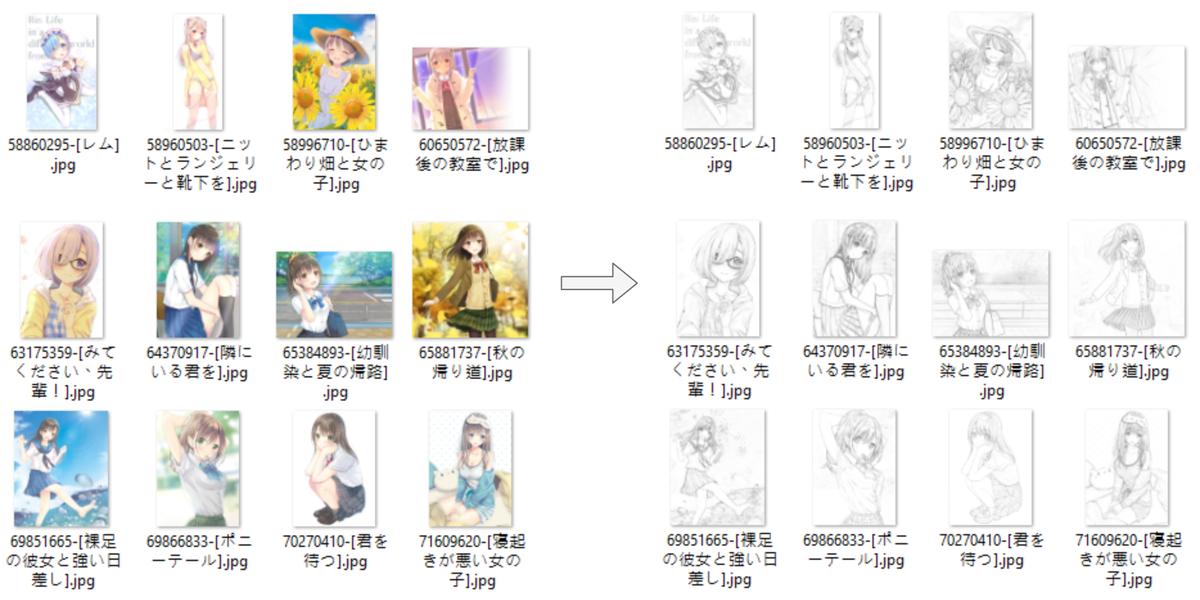
Results
After training for 170 epochs, the following are some of the generated results using the testing dataset:







3. Color Hints
As you can see, the above generator only paints the input image with arbitrary colors. However, what if we want to paint a specific part of the artwork with a specific color? Can we provide some color guides to the input such that the generator knows how to paint the image with our desired colors?
Of course, we can, but we have to include the color hints in the inputs when training the model such that it learns a mapping: non-colored image + color hints → colored image. But how do we create the color hints? Well, my idea was to draw some color dots on the decolorized image (or on a new separate image) in random positions. Then we train our model again with these processed images.

We first concatenate the non-colored image with its color hints image, and then feed them into our model to train it just like what we did previously.
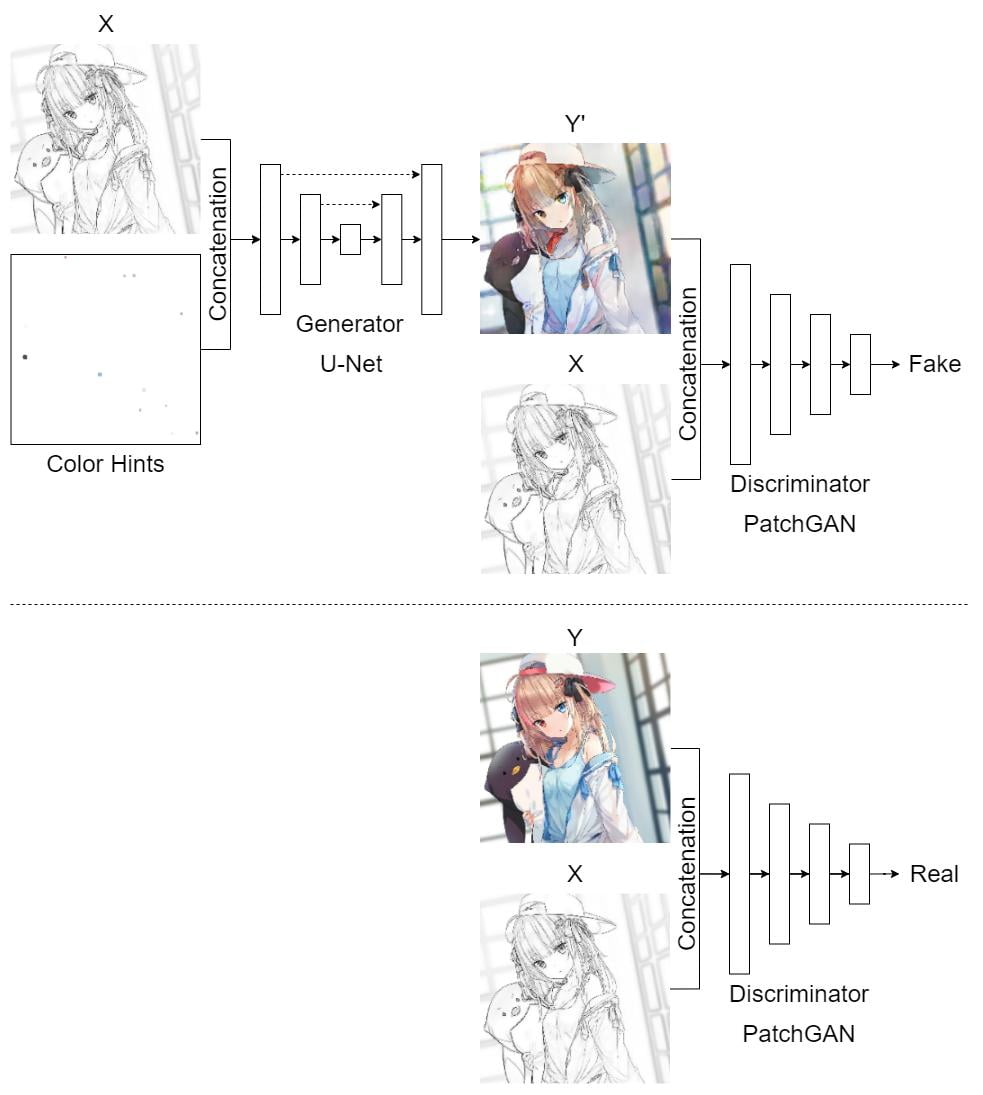
Results
The following are the results after training for 120 epochs:




![source: 桜と巫女 by [みゅとん]뮤우톤](https://codoraven.com/app/uploads/2023/02/20_pix2pix_hints_result_5.jpg)
4. Conclusion
The colorization results using Pix2Pix are pretty cool, but obviously not good enough. There are several things needed to be solved and enhanced in the future:
- Colors sometimes leak into surrounding areas
- Create a larger and cleaner dataset
- Try to make it in higher resolution
- Try other model architectures
As a beginner in deep learning, I have learned a lot from working on this project and I will continue to search for a better solution to this task. Hopefully, I can share this project later with you again. Thank you for reading.





